With the latest version of Imixs-Workflow (6.2.0) we upgraded to GraalVM 24.1.2 and Widlfly 29.0.1-Final-JDK-17.
Wildfly 29 requires GraalVM in version 24.1, as the polyglot version ‘24.1.2’ is no longer compatible to older Truffle version ‘23.1.1’. Wildfly 29 comes also with a lot of bugfixes and minor improvements. In this way Wildfly has now become a bit stricter in dealing with some older packages from the JDK or Java SE version. To be able to execute Scripts with the GraalVM polyglot language engine you need to enable the global modules feature. Just add the module ‘jdk.unsupported’ to your ee subsystem config in standalone.xml:
With our new project Imixs E-Invoice we provide an easy to use pure java library to read and write e-invoice documents in XML.
Imixs E-Invoice stands out for its independence from external dependencies. In contrast to libraries like the Mustang project Imixs E-Invoice does not have any external dependencies. The library seamlessly integrates into modern Java projects and makes it a good choice for custom projects and adapters.
Imixs E-Invoice supports the major European e-invoice standards factur-x (CII) and UBL. To get started just add the Maven dependency:
Now you can read any e-invoice xml document and translate it into a EInvocieModel
EInvoiceModel eInvoiceModel =null;
try (InputStream is = myInputStream) {
if (is == null) {
throw new IOException("Resource not found" );
}
eInvoiceModel= EInvoiceModelFactory.read(is);
}
// Verify the result
assertNotNull(eInvoiceModel);
assertEquals("R-00010", eInvoiceModel.getId());
LocalDate invoiceDate = eInvoiceModel.getIssueDateTime();
assertEquals(LocalDate.of(2021, 7, 28), invoiceDate);
assertEquals(new BigDecimal("4380.9"), eInvoiceModel.getGrandTotalAmount());
assertEquals(new BigDecimal("510.9"), eInvoiceModel.getTaxTotalAmount());
assertEquals(new BigDecimal("3870.00"), eInvoiceModel.getNetTotalAmount());
// Test SellerTradeParty
TradeParty seller = eInvoiceModel.findTradeParty("seller");
assertNotNull(seller);
assertEquals("Max Mustermann", seller.getName());
assertEquals("DE111111111", seller.getVatNumber());
You have full access to the XML tree behind by using standard Java xml dom objects:
// get the w3c Dom Document
Document xmlDocument = eInvoiceModel.getDoc();
// get the root Element
Element root = eInvoiceModel.getRoot();
Write a E-Invoice XML Document
You can also create a e-invoice document by simply using XML templates. To create a new e-invoice document you can work with any valid e-invoice template as an XML file. The template is the base for the core model that can be updated by the library. See the following example code:
// read the XML Template
EInvoiceModel model = EInvoiceModelFactory.read(new ByteArrayInputStream(myXMLTemplate));
// Update data
model.setNetTotalAmount(100.00);
model.setTaxTotalAmount(19.00);
model.setGrandTotalAmount(119.00);
model.setIssueDateTime(myInvoiceDate);
model.setId("R-10000");
// Addresses
TradeParty billingAddress = new TradeParty("buyer");
billingAddress.setName("Max Mustermann");
billingAddress.setPostcodeCode("1000");
billingAddress.setCityName("Berlin");
billingAddress.setStreetAddress("Lindenstr. 1");
model.setTradeParty(billingAddress);
// Invoice Items
TradeLineItem tradeLineItem = new TradeLineItem("1");
tradeLineItem.setName("Moon Rocket");
tradeLineItem.setDescription("Fly my to the moon");
tradeLineItem.setGrossPrice(1000000.00);
tradeLineItem.setQuantity(1.0);
tradeLineItem.setVat(19.0);
tradeLineItem.setTotal(1000000.00);
model.setTradeLineItem(tradeLineItem);
// finally update the template file
byte[] myEInvoice=model.getContent();
Join the Project
We maintain Imixs e-invoice as an open source project on GitHub and welcome you to join our community. Whether you want to fix bugs, add new features, or improve documentation – your contributions are valuable to us. You can start by forking the repository, creating issues for bug reports or feature requests, or submitting pull requests with your improvements. We actively review contributions and provides feedback to ensure high code quality.
We are currently creating a completely new modelling opportunity within the Imixs workflow project. This new web based modelling approach is build on top of the impressive open source project bpmn.io.
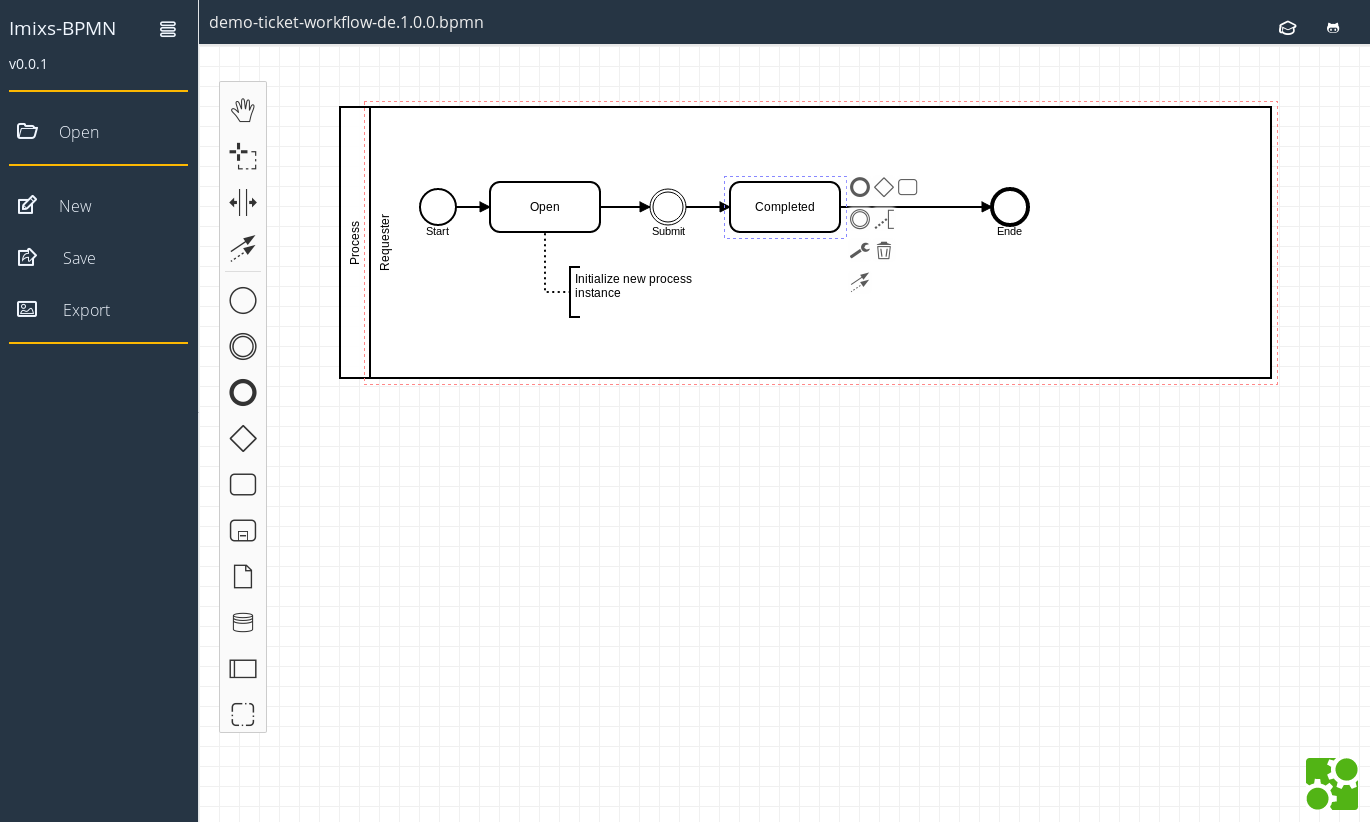
BPMN Models created in Eclipse with the existing powerful Imixs-BPMN Modeller can be viewed and modeled directly in the web based modeler and vice versa.
The new project Imixs-BPMN.io is hosted on Github. The goal is to transfer more and more functionality from the Eclipse Platform to the web-based solution. We are only at the beginning and are grateful for any kind of support. We invite you to join the project!
The Imixs-Workflow engine has a build-in metric service which is based on lates vdrsion of Eclipse Microprofile 3.2. This metric service can be used to monitor the Imixs-Workflow engine and its running processes. The Imixs Metric Service provides fine-grained metrics to monitor individual business processes or even individual process steps within a specific workflow.
The Data format is based on the common Prometheus format and can be analyzed in real-time with different kind of Tools.
Howto Setup
To setup the imixs-metrics you just need to enable the metric service by a environment variable:
METRICS_ENABLED: "true"
The Imixs-Workflow engine will start automatically collecting all relevant metrics during document updates or the processing life-cycle of a custom business process.
The Metrics are available on the metrics api endpoint of the application server. For Wildfly this endpoint is for example:
http://localhost:9990/metrics
Next you can start a Prometheus Server to collect the metrics by using the following prometheus.yml file:
global:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: 'imixs-monitor'
# Imixs-Microservice - payara metrics
- job_name: 'imixs'
scrape_interval: 5s
metrics_path: /metrics
static_configs:
- targets: ['imixs-workflow:8080']
# Imixs-Microservice - wildfyl metrics
#- job_name: 'imixs'
# scrape_interval: 5s
# metrics_path: /metrics
# static_configs:
# - targets: ['imixs-workflow:9990']
Note: that for wildfly the metrics_path and target port differs from the payara config!
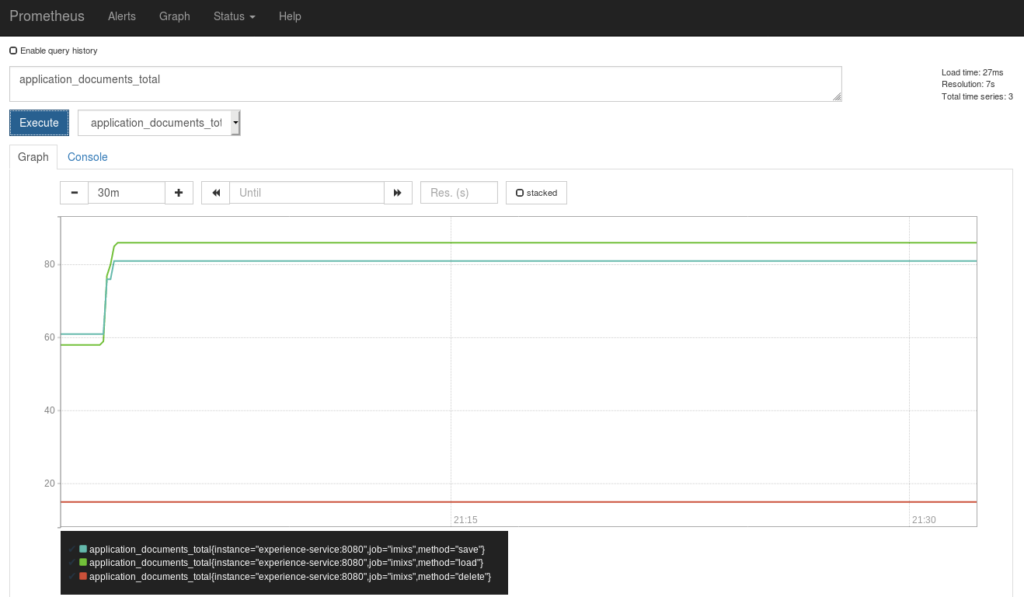
This will collect metrics from the service endpoint ‘http://imixs-workflow:8080/’. Prometheus will scrape the metrics every 15 seconds and stores the result into its own database.
From the Prometheus Dashboard you can test the data within your web browser:
Monitoring Metrics with Grafana
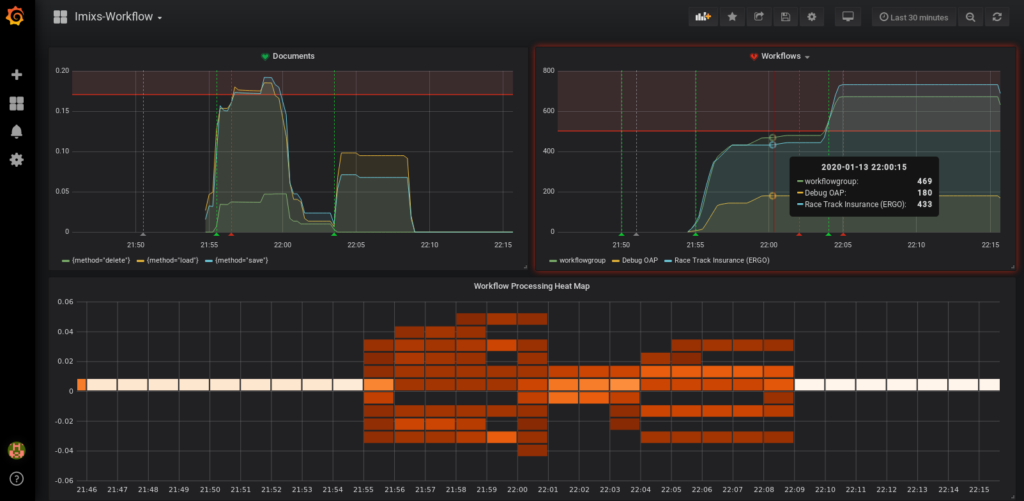
To monitor you workflow you can easily connect your Prometheus server with a Grafana Instance. This allows you to visualize your metrics in an individual and more detailed dashboard.
There are a huge amount of functions available in Grafana to analyze and monitor data. You can also activate individual alerts to notify your process owner about the load of your business processes.
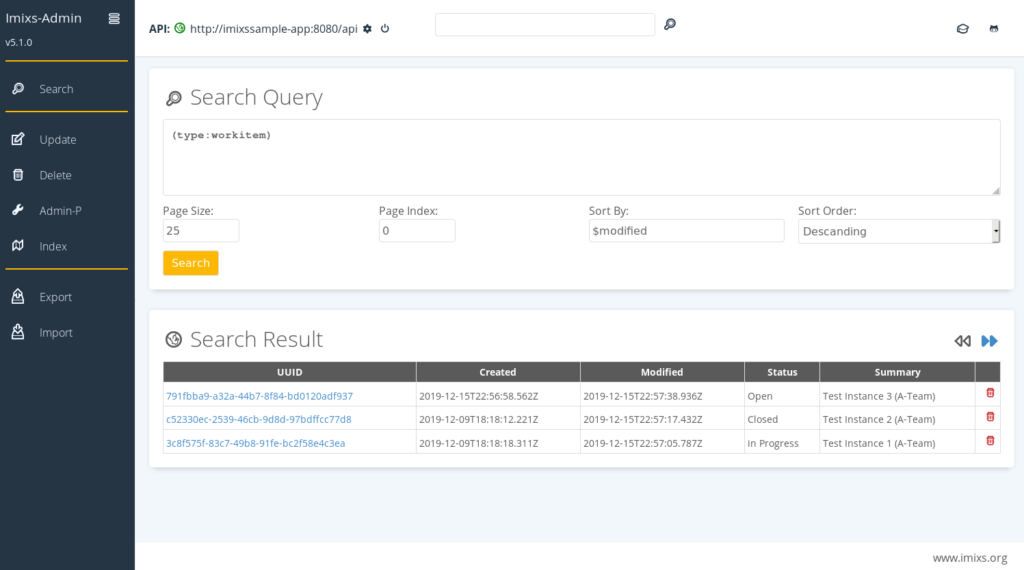
As always, the Imixs-Admin Client also shows insights how to build modern, lean web interfaces based on the Imixs Rest API. The new version is realized as a Single-Page-Application using the Imixs-Script library. The self-contained microservice can connect to any Imixs-Workflow instance via Rest. The backend also integrates the latest version of the Imixs-Melman sub project.
The project is available on Github. Imixs-Admin 5.1 will be evolved with new features in the upcoming releases.
We proudly announce out latest release of Imixs-Workflow. Version 5.1 is a big step forward on the road to greater flexibility and support for a modern microservice architecture.
Imixs-Workflow 5.1 introduce a new indexing concept that allows to provide different implementations for a full-text-search and structured-search. Now users can switch between the Apache Lucene Core search engine or the Apache Solr Search engine. Solr is a highly reliable, scalable and fault tolerant search engine. Solr supports distributed indexing, replication and load-balancing. Especially for a high scalable microservice architecture this search engine is the best choice.
Also the support for Eclipse Microprofile is now completed. With Eclipse Microprofile microservices and business applications can be developed faster and more resilient. Build on Eclipse Microprofile and Jakarta EE now Imixs-Workflow can be deployed on all modern application servers and is tested with Payara, Wildfly, OpenLiberty, TomEE.
Version 5.1. is already included in the latest version of Imixs-Microservice which provides a lightweight architecture for business transaction in a microservice environment.
The Imixs-Workflow project supports now a native integration Adapter for Apache Kafka. With this feature asynchronous messages can be handled within a complex business process.
Apache Kafka is a distributed streaming platform. This means you can publish and subscribe to streams of records, similar to a message queue or an enterprise messaging system. Apache Kafka store streams of records in a fault-tolerant durable way and process streams of records as they occur. Kafka is generally used for two broad classes of applications:
Building real-time streaming data pipelines that reliably get data between systems or applications
Building real-time streaming applications that transform or react to the streams of data
The Imixs-Kafka Adapter integrates Kafka in a native way and allows the producing and consuming of Imixs-Workflow Messages.
Workflow Message Autowire
With Imixs-Kafka you can easily setup a scenario where Workflow Messages are generated automatically during the processing life-cycle. With the Autowire-Function new process instances are send into a Kafka Message Queue so that any consumer interested in workflow events can consume the message and react in various ways.
The Adapter filters Workflow events by the Model Version number so you can control which kind of workflows are send into a message queue.
Workflow Messages based on Business Logic
Another way to send Workflow Messages into a Kafka queue is the Imixs-Adapter Class. This implementation is based on the Imixs-Adapter concept and allows a more fine grained modeling of an asynchronous service integration. The Imixs-Kafka Adapter can be configured directly in a BPMN 2.0 Model.
This modeling approach allows you to setup complex workflow scenarios with a asynchronous communication.
Sending Workflow Events With Kafka
The other way to integrate Imixs-Workflow into a Kafka infrastructure is to send Workflow Messages to a Kafka queue to be processed by the Imixs-Workflow Instance. In this way a client sends a Process Instance with a predefined topic into a Kafka Message queue.
Imixs-Workflow will automatically consume those messages and process the workflow data. In this way messages can be used to trigger the event-based Imixs-Workflow engine. The following example shows how a client can send a workflow event for a named topic:
The Imixs-Kafka Adapter is a powerful feature to integrate Imixs-Workflow in a Microservice Infrastructure based on Publish-Subscribe Messaging Queues. With Apache Kafka a fault-tolerant and scalable messaging platform can be adapted to Saga Transactions based on a BPMN 2.0 model.
If you have any questions or your need help to integrate Imixs-Workflow into your Microservice Architecture you can join the project on Github.
The Imixs-Workflow engine provides different ways how you can store and access business data within a business process. In the following short tutorial I will show up to ways how to do this.
Today we released the new Version 4.5.0 of Imixs-Workflow. The version now has a full support of Java EE7. The release also includes also several improvements in JSF components and The Rest-API. Here is an overview about the latest changes:
New Features
The XMLItem now supports mixed value lists
New Extend FileData Object with custom attributes
LuceneUpdateService – provides a new ItemAdapter class to improve the extension mechanism
Full Java EE7 Support
Performance improvements for the imixs-faces module
RestService supports now custom reports to open spread sheets
Enhancements
JobHandlerRebuildIndex – allows to overwrite the Block_Size and Time_out
A data migration is not needed. Existing applications can switch directyl to 4.5. Only JSF modules should adapt the new JSF Controllers. You can find details here.
With the new project Imixs-Mock you can now simulate your Imixs-Workflow BPMN models in an easy way. The project provides a full mock of the Imixs-Workflow engine and allows to test and simulate different workflow scenarios. Imixs-Mock simulates the full processing life-cycle including all workflow plug-ins. You can specify also a subset of plug-ins to test specific business logic in your workflow project.
To add the mock into your own workflow project just add the following dependencies:
The Imixs-Mock allows you to simulate different users processing a process instance. In this way you can verify the Access Control List (ACL) of a process instance and the assignment of process owners in complex workflow scenarios.