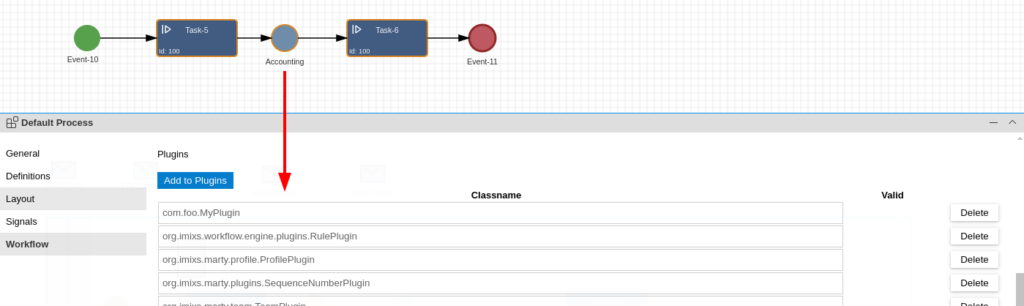
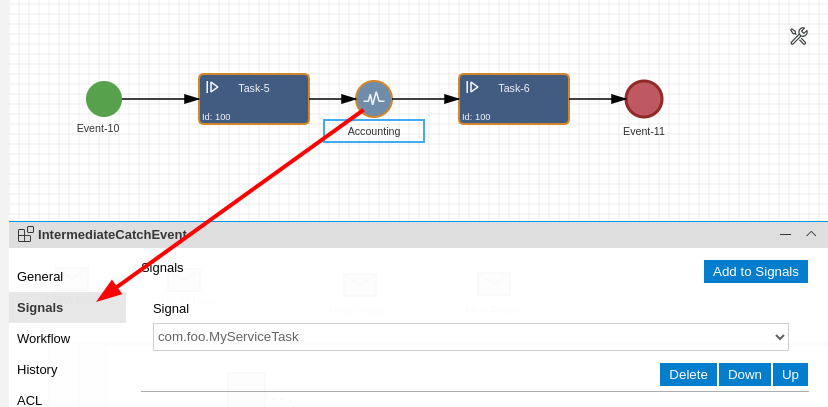
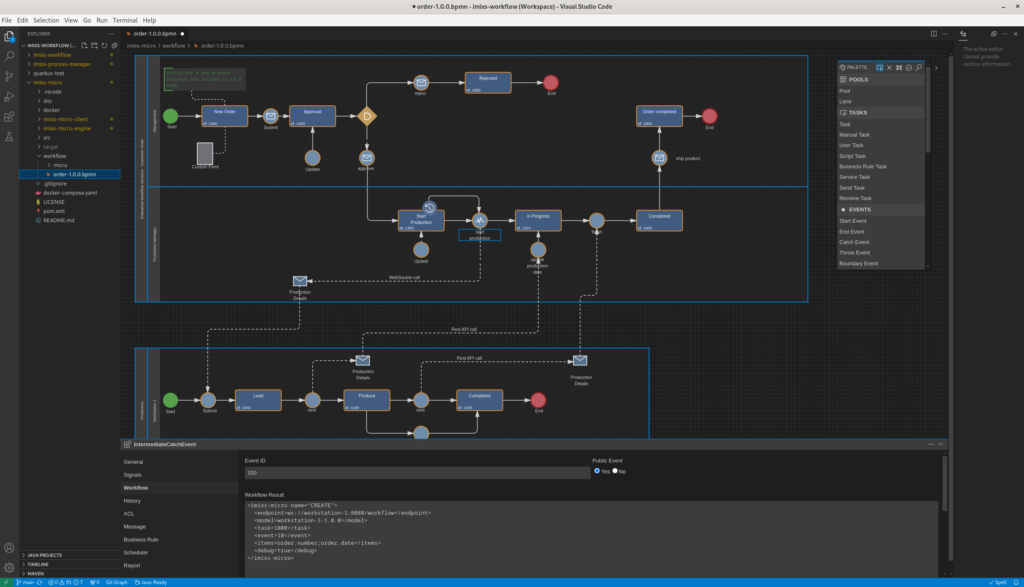
With our latest version of Imixs Workflow, we introduce a game-changing approach to business process automation, enabling domain-specific handling of BPMN 2.0 conditions.
The Challenge
In previous versions, conditional sequence flows in the Imixs Workflow engine —as in most traditional BPMN engines — could only be defined using script functions. While this scripting-based approach offered flexibility, it also introduced several limitations:
- Domain-specific languages could not be supported
- Conditions were tightly coupled to technical implementation
- Adding new evaluation logic required modifying or extending engine code
- Complex business rules were difficult to express and maintain
These constraints made it challenging to adapt and extend business logic across different domains.
The Solution: CDI Event-Driven Condition Evaluation
Imixs Workflow now introduces a revolutionary and extensible architecture for condition evaluation. Leveraging Jakarta EE’s CDI (Contexts and Dependency Injection) events, conditions can be transformed and interpreted by specialized observers before evaluation — all without modifying the core engine.
This new approach not only supports functional scripting, but also enables fully domain-specific evaluation of BPMN 2.0 conditions, such as SQL-based queries, external API calls, or even AI-driven logic.
How It Works
When a sequence flow condition is encountered, the system fires a CDI event that any registered observer can intercept and handle. Observers can:
- Translate domain-specific languages into executable code
- Implement business rule languages tailored to specific domains
- Add validation, monitoring, and auditing layers
- Integrate external services and rule engines
Real-World Example: Domain-Specific Conditions
Instead of writing complex JavaScript like this :
// Before: Hard-coded and difficult to maintain
!['AT', 'BE', 'BG', 'HR', ...].includes(workitem.getItemValueString('country'))You can now define business rules in a domain-specific language:
SQL: SELECT COUNT(*) FROM eu_countries WHERE country_code = ? > 0A specialized domain observer intercepts this rule and translates it into the appropriate JavaScript. The beauty? The RuleEngine doesn’t need to know anything about domain-specific languages — it simply evaluates the resulting JavaScript as it always has.
Implementation Example
The new event-driven design of Imixs Workflow is built on Jakarta EE’s CDI (Contexts and Dependency Injection) event mechanism — a core implementation of the Observer Pattern. This means that custom components can observe and react to condition evaluation events without depending on the workflow engine itself.
Creating your own domain-specific observer is straightforward. Simply extend the new ConditionalExpressionEvent class and implement your logic as a CDI observer method:
@ApplicationScoped
public class DepartmentSQLRule {
public void onConditionEvaluation(@Observes ConditionalExpressionEvent event) {
String condition = event.getCondition();
if (condition.startsWith("SELECT ")) {
// Transform domain-specific rule into JavaScript
String javascript = translateSQLRule(condition, event.getWorkitem());
event.setCondition(javascript);
}
}
}
In this example, the observer listens for every ConditionalExpressionEvent. If the condition starts with an SQL statement, it automatically transforms the domain-specific rule into executable JavaScript. Because this is handled entirely via CDI events, the core RuleEngine remains untouched — ensuring maximum flexibility and extensibility.
Opening Doors for Enterprise Development
This new observer-based architecture fundamentally changes how enterprise workflow systems are developed and evolved. By decoupling condition evaluation from the core engine, organizations gain unprecedented flexibility in how business rules are expressed, validated, and executed. Teams can now create tailored domain-specific languages that speak the language of their business domain—whether that’s banking regulations, insurance underwriting, supply chain logistics, or healthcare compliance.
The plugin-based approach means that new capabilities can be added without touching the workflow engine itself. Observers can be developed independently, tested in isolation, and deployed without impacting existing systems. This enables enterprises to build sophisticated, multi-layered workflow systems where each layer serves a specific purpose: one observer might handle compliance validation, another translates business rules into executable code, a third provides audit logging—all working seamlessly together.
The possibilities are as diverse as the challenges enterprises face. Complex routing logic that once required extensive JavaScript development can now be expressed declaratively. Integration with external rule engines and services becomes straightforward. Most importantly, subject matter experts and business analysts can participate directly in defining and maintaining business rules, reducing the gap between business requirements and technical implementation.