
Everyone is talking about cloud technologies and of course every modern project relies on a microservice architecture. A variety of technologies and methods contribute to the success of this architecture pattern. But what does cloud native actually mean for the business world? How do companies and organizations implement business processes successfully beyond the big technology promises?
The basic idea of a microservice architecture is to break down the technical requirements of a software system into the smallest possible and therefore manageable services. The advantage: services created in this way can be developed independently of each other with different technologies by different teams. At the same time, we see new methods and technologies to connect, monitor and scale these services.
But just looking at the technology does’t mean that software can be developed faster and better. I would therefore like to compare some of these methods and technologies from the microservice architecture with the requirements for the development of business applications.
Domain Driven Design
The separation of a software system into small, manageable services is a challenge when building cloud- and microservice architectures. In the course of rapid development, the concept of domain driven design (DDD) is becoming more and more important. DDD was developed back in 2003, well before the rise of microservice architecture. The idea behind it: Business logic and complex data relation is described in smaller blocks and in a domain-neutral manner. This fits perfectly with the microservice architecture and is often expressed by the term bounded context. The bounded context describes the bounderies of a microservice – for example its purpose and the underlying database schema.
With the help of DDD and the bounded context, architecture can build a bridge to the technical requirements. For later success, take care always considering DDD regardless of the technical requirements.
Resilience, Monitoring and Inter-Service-Communication
Once a new microservice has been defined, it is all about the technical implementation. There is a large number of methods and technologies which simplify the implementation. When using modern microservice frameworks, such as Eclipse Microprofile, topics like resilience, monitoring or inter-service communication are automatically included. As a result, the teams can concentrate on the implementation of business requirements.
There are also a variety of concepts and platforms to manage and run the new services . This is how Docker has established itself as the standard for building a service. There are new powerful operating models, such as Docker Swarm or Kubernetes. These concepts help to run the services in an isolated environment and scale them as needed.
The monitoring of a single service can also be further optimized via so-called service mesh platforms. For example, platforms such as Istio help to monitor and to control the data traffic to and from the service.
So everything is fine …? Unfortunately not!
In view of all these technologies, one can get the impression that now (once again) all problems are solved. But distributed systems always increase the complexity. This applies in particular to cloud- and microservice architectures. Building a more complex business process that spans multiple services, quickly becomes a new challenge. The advantage of microservices – namely the separation into smaller services with distributed responsibilities – generates a completely new problem: Who is now responsible for the correct execution of a long-running business process? How can you ensure that data is consistent across all service boundaries? How is data distributed and exchanged within a transaction?
Sagas
Once you leave the isolated view of your own microservice, you usually find that a cloud architecture brings completely new challenges. If several services are linked together, you quickly come across the problem of long-running transactions going beyond the bounded context of a single service. Transactions are an integral part of any non-trivial business application. Without transactions, it would be impossible to maintain data consistency in a distributed system. The ACID transactions (atomicity, consistency, isolation, durability), known from the world of relational database systems, solve the problem by giving the illusion that every transaction has exclusive access to the data. Even in a microservice architecture, ACID transactions are often used within a single service. However, the challenge is to implement transactions for operations that update data not limited to a single service.
Distributed Transactions
The traditional approach to maintaining data consistency across multiple system components is defined a distributed transactions. The XA standard offers the concept of two-phase commit (2PC) to ensure that all participants of a transaction either commit or roll back there data. Such an XA technology stack consists of XA-compatible databases and message brokers, database drivers and APIs, as well as inter-process communication that passes a global XA transaction ID. Most SQL databases are XA compatible, as are some message brokers. For example, JTA is used within Java EE applications to support distributed transactions.
However, the use of distributed transactions did not work in modern cloud-based architectures. The problem: Many newer technologies, including NoSQL databases like MongoDB and Cassandra, as well as news brokers like RabbitMQ or Apache Kafka do not support XA, so XA does not offer a solution. But how can the lack of data consistency within a distributed service architecture be solved?
The Data Consistency
The “Saga Pattern” is a mechanism to maintain the data consistency within a microservice architecture. A saga describes a sequence of local transactions to update data across multiple services. Each local transaction first updates the data within its own context using an ACID transaction. The saga describes the sequence of updates within one transaction. On the other hand, data that has already been committed by a single service has to be rolled back in case of an failure of another service. In this way the sage is ensuring the data consistency of the entire system.
Howto Compensate Transactions and to Undo Changes
In contrast to a local ACID transaction, transactions cannot be easily rolled back in a microservice architecture, since every service keeps its changes locally.
This means that as soon as a local transaction fails within one business transaction, the saga must explicitly undo the local transactions that have already been committed and the changes made by the other participants.
This is known as transaction compensation and is an important concept to maintain data consistency within a long-running business process:
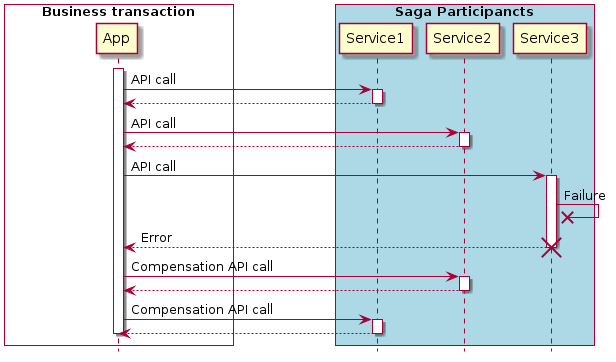
How to Coordinate Sagas?
The implementation of a saga consists of business logic that coordinates the steps during the saga. Once a saga has started, it must select the first participant and instruct it to perform a local transaction. As soon as this transaction is completed, the next participant can be called. This process continues until all steps within a saga have been completed. If a local transaction fails, the saga must perform the so-called compensation actions in a reverse order.
There are basically two variants of how the coordination logic can be implemented in a saga:
– Choreography – The business logic is distributed among the Saga participants. Communication between the participants takes place primarily through the exchange of events.
– Orchestration – The business logic is controlled centrally in an independent orchestrator service.
Choreography
When using choreography as coordination logic, a saga participant subscribes to the events of the other participants and publishes events by himself. A central message broker is therefore required for a reliable event-based communication.
The problem is to ensure that a saga participant can map every received event onto its own data. For example, when an order-service receives an event from the credit card service to authorize the payment, it must be able to look up the corresponding order. The solution can be a correlation ID as part of a published event that enables all the participants to perform a local data mapping.
Even if this type of coordination logic seems simpler at first glance, it is more difficult to understand in practice because there is no single place in the code that fully describes the saga. Instead, the business logic of the saga is distributed among the services and their implementation. As a result, it is sometimes difficult for a developer to understand how a particular saga works. At the same time, the concept leads to a closer coupling, since each Saga participant must know the events of the other participants in order to subscribe to them.
Orchestration
Orchestration is an alternative way to implement a saga. When using orchestration, it is the responsibility of a saga orchestrator to tell saga participants what to do. The Saga Orchestrator itself acts as a microservice that communicates with the participants either synchronous or asynchronous. With each new process step, the orchestrator calls a specific participant. After the Saga participant has performed its operation, the saga orchestrator determines which step in the saga must be performed next.
A saga orchestrator can be modeled as a state machine. Every status can be described as a ‘task’, the transitions between the states as ‘events’. Each event calls up a specific saga participant.
The advantage: The saga orchestrator calls the API of the participants directly and does not have to be informed via external events. As a result, the orchestrator depends on the participants and not vice versa. The participants themselves have no knowledge of the saga. As a result there is less coupling and there is no risk of cyclical dependencies.
Dealing with the Lack of Isolation – ACD
One challenge when using sagas is to deal with the lack of isolation of ACID transactions. The updates made by a local transaction within a saga are immediately visible to other participants. This behavior can cause two problems:
– other participants can change data that the saga accesses during execution.
– other subscribers can read data before all updates have been completed, and thus be exposed to inconsistent data.
This is why we speak of ACD transactions. So here the ‘I’ for isolation is missing.
The lack of isolation can actually lead to anomalies, which sounds not like a practical situation. In practice, however, it is common for us to accept less isolation in distributed business processes in order to achieve higher performance. This concept is often described as “eventual consistency” and is used by many distributed database systems.
In the end, this problem can only be compensated if the participants do not call each other, but are only triggered by the saga orchestrator.
The Interaction Pattern
Now the question is, how exactly does the saga orchestrator interact with its participants? There is a variety of client-service interaction styles. These can be divided into two dimensions.
The first dimension describes whether the interaction is 1: 1 or 1: n:
• One-to-one – each request is processed by exactly one service.
• One-to-many – Each request is processed by several services.
The second dimension determines whether the interaction is synchronous or asynchronous:
• Synchronous – The client expects a timely response from the service and blocks further execution.
• Asynchronous – the client does not block and the response is not necessarily sent immediately.
If we consider the saga orchestrator pattern, the following types of interactions can be defined:
• Synchron Request / Response – The orchestrator makes a request to a participant and waits for a response.
• Asynchronous Request / Response – The orchestrator sends a request to a participant who does not respond asynchronously but immediately.
• One Way Notification – The orchestrator sends a request to a participant without waiting for a response.
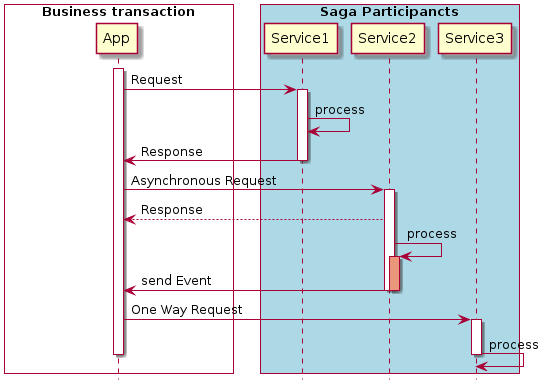
In practice, each individual Saga participant can also use a combination of these interaction styles.
BPMN
The next question is, how can the saga pattern be implemented within a microservice architecture? As mentioned above, the coordination logic of a business process can be described using a state machine.
The Business Process Modeling Notation – BPMN for short – has established itself as the de facto standard. With the help of BPMN, on the one hand, a non-technical business process can be described, on the other hand, BPMN also offers the possibility to store technical implementation details within a model. This makes a model executable in a software system.
The Open Source project Imixs-Microservice combines the BPMN modeling concept with the idea of a Saga Orchestrator. Imixs-Microservice is based on the Imixs workflow engine.
A Saga as a Process Model
With the Imixs-Microservice a saga is described with the help of BPMN. Each status within the saga is described via task elements. The API calls of the individual saga participants are mapped using events.
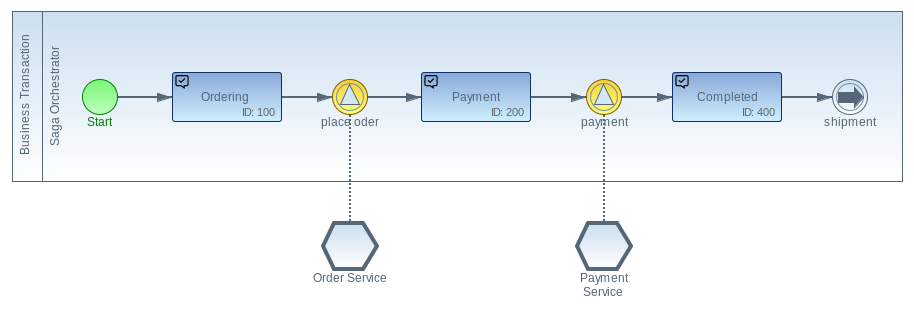
The example above shows an extract from an online ordering process:
1. With the initial task ‘Ordering’ the transaction is started and is therefore under the control of the saga orchestrator.
2. The event ‘place order’ calls the 1st Saga participant ‘Order Service’ to include the order in the OR management.
3. The transaction is then in the ‘Payment’ status.
4. The event ‘payment’ triggers the payment via the 2nd Saga participant ‘Payment Service’.
5. The transaction ends with the status ‘Completed’.
The two Saga participants ‘Order Service’ and ‘Payment Service’ do not know each other and are decoupled by the Saga Orchestrator.
Deployment
The Imixs microservice is available on Github and can be started via Docker-Compose together with a process model:
$ git clone https://github.com/imixs/imixs-microservice.git
$ cd imixs-microservice
$ docker-compose upA new saga can then be started by calling the Rest API. In addition to specifying the model to be used, technical information on the processing of the saga can be provided. For example the order number:
$ curl --user admin:adminadmin -H "Content-Type: application/json" -H 'Accept: application/json' -d \
'{"item":[ \
{"name":"$modelversion","value":{"@type":"xs:string","$":"1.0"}}, \
{"name":"$taskid","value":{"@type":"xs:int","$":"1000"}}, \
{"name":"$eventid","value":{"@type":"xs:int","$":"10"}}, \
{"name":"order_id","value":{"@type":"xs:string","$":"xxxx-yyyy"}}\
]}' \
http://localhost:8080/api/workflow/workitemThe newly started saga is now subject to the transaction control of the saga orchestrator, which persists the state of the saga through its own ACID transactions. The respective API calls are managed via events. As a result, an individual API call can be assigned to each event within a model.
The API call itself is implemented by an adapter class using one of the interaction patterns described bevore:
public class PaymentAdapter implements SignalAdapter {
@Override
public ItemCollection execute(ItemCollection document, ItemCollection event) throws AdapterException {
// payment api call
....
}
}The so-called ‘SignalAdapter’ is linked via the BPMN model and is called up by the Imixs-Workflow engine on the corresponding event. The result of such a external API call goes back into the domain object of the saga orchestrator which controls the further execution by business rules. For example with a gateway, it is possible to ask for the order amount and to decide whether a credit validation is necessary or not. This all can be described completely within the model and without hard coded business logic.
Error Handling with Compensations
But how does all this work in case a single transaction like the ‘payment’ fails?
In this case, we need to ensure the data consistency. The orchestrator need to undo the previous service call to the ‘Order Service’ by initiating a compensation. With the help of BPMN, this can be modeled with a corresponding gateway and an additional event like shown in the following example:
If service call to the Payment Service fails, the compensation event ‘cancel order’ is triggered. This calls the Saga participant ‘Order Service’ again to cancel the order. The business transaction stops. The corresponding business logic can either be implemented directly in the adapter or be describe as a business rule within the model.
In practice, any complex business processes can be modeled in this way. Since the actual transaction control is now available in a model, changes and new requirements can be added without adapting the implementation of the individual service participants. The API calls themselves are made by adapter classes, which are called by the Imixs-Microservice.
Conclusion
Cloud-native architectures today offers a variety of technologies and frameworks. However, the question remains how the increasing complexity of a microservice architecture can be managed when implementing a concrete business processes. The Saga Pattern offers a perfect solution. With the help of a modern workflow engine, even long-running complex business processes can be managed easily.
With Imixs-Microservice a complete saga orchestrator based on BPMN 2.0 can be integrated into a microservice architecture. Based on a model driven approach new services can be connected via the adapter pattern and business logic can be described with business rules. In this way any business process can be changed without changing the implementation of individual services.
One Reply to “Cloud Native and Business Transactions”